Uma empresa chinesa está humilhando o GPT-5 em matemática. E cobra 45 vezes menos.
DeepSeek V3.2 bate GPT-5 em matemática e código multilíngue, custa US$0,028 por milhão de tokens e é open source. Os números explicam por quê.


Os benchmarks do DeepSeek V3.2 contra o GPT-5 chegaram, e os números são o tipo de coisa que faz engenheiro de prompt trocar de API no mesmo dia. A startup chinesa de Hangzhou está batendo o modelo mais caro da OpenAI em raciocínio matemático e código multilíngue - e cobrando uma fração do preço. Vamos aos dados.
Os números que importam
O DeepSeek V3.2-Speciale, a variante mais agressiva do modelo, alcançou 96,0% no AIME 2025 (American Invitational Mathematics Examination). O GPT-5 High ficou em 94,6%. No Harvard-MIT Mathematics Tournament, o placar foi 99,2% contra 97,5% do Gemini 3 Pro. Em competições internacionais, o DeepSeek conquistou medalha de ouro no IMO 2025 com 35 de 42 pontos, segundo lugar no ICPC World Finals e 10a posição no IOI com 492 de 600 pontos.
Em código, o cenário é mais equilibrado. No LiveCodeBench, o GPT-5 leva vantagem com 84,5% contra 83,3% do DeepSeek. Mas no SWE Multilingual - que testa código em múltiplas linguagens, não só Python e JavaScript - o DeepSeek abre 15 pontos: 70,2% contra 55,3%. No Codeforces, o modelo atingiu rating 2701, classificação Grandmaster.
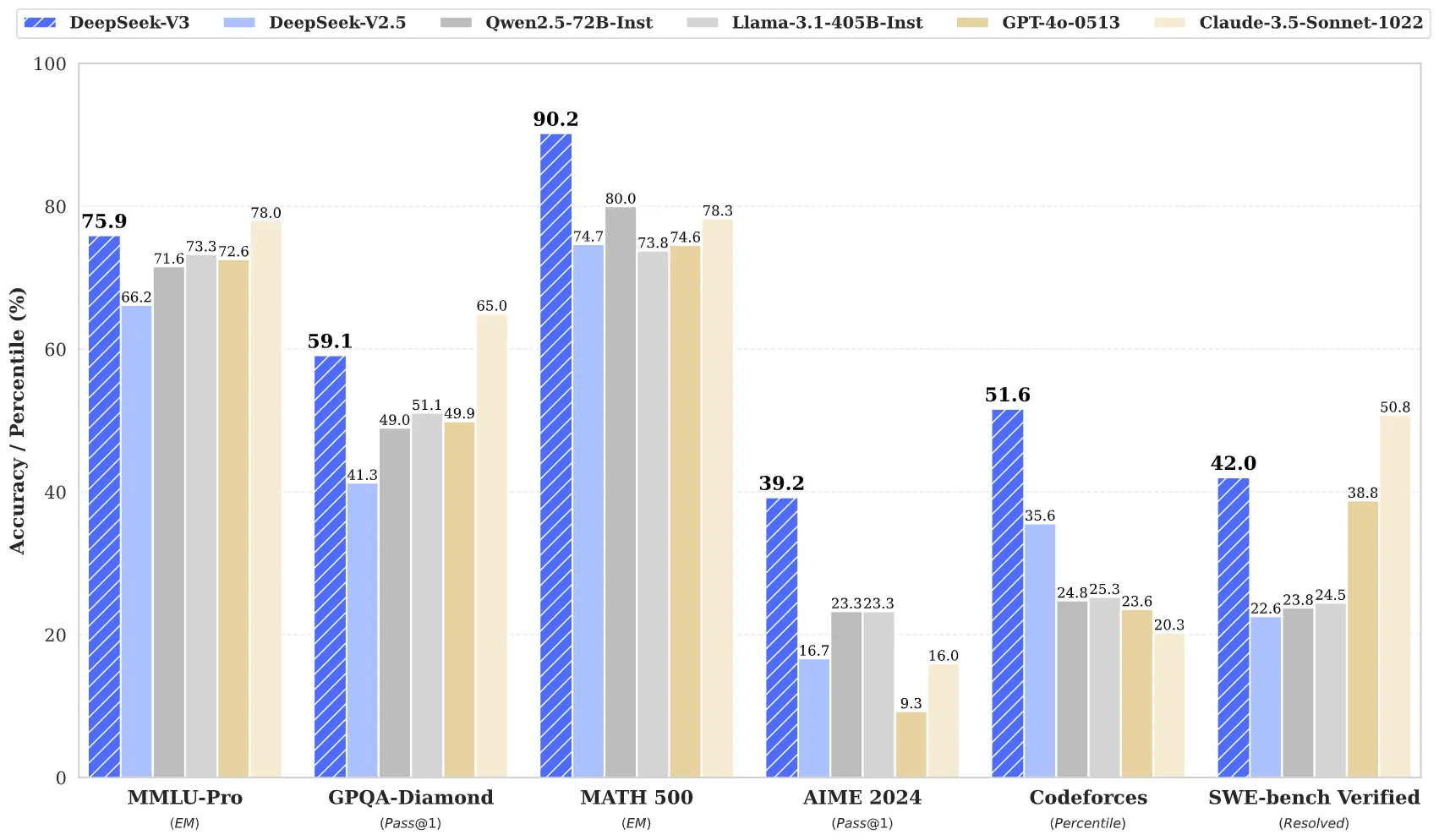
A tabela de preços que dói
Aqui é onde o argumento muda de “interessante” pra “urgente”:
| Modelo | Input (por milhão de tokens) | Output (por milhão de tokens) |
|---|---|---|
| DeepSeek V3.2 (cache) | US$0,028 | US$0,42 |
| DeepSeek V3.2 (padrão) | US$0,28 | US$0,42 |
| GPT-5 | US$1,25 | US$10,00 |
| Claude Opus 4.1 | US$15,00 | US$75,00 |
Na prática, uma tarefa com 100 mil tokens de entrada e 100 mil de saída custa US$0,07 no DeepSeek e US$1,12 no GPT-5. Com cache ativo, a diferença chega a 31 vezes. Pra quem roda milhões de requisições por mês, a economia não é percentual - é ordem de magnitude.
E o custo de treinamento? A DeepSeek treinou o V3 por US$5,5 milhões usando 2,788 milhões de horas de GPU H800. Modelos concorrentes de fronteira custam acima de US$100 milhões. Uma redução de 95% no custo de treinamento que se traduz diretamente no preço da API.
Como funciona por dentro
O V3.2 usa arquitetura Mixture-of-Experts com 671 bilhões de parâmetros totais, mas ativa apenas 37 bilhões por token. São 256 redes especialistas por camada, das quais 8 são ativadas por inferência - 1 a 2 compartilhadas e 6 a 7 roteadas dinamicamente.
A sacada técnica que merece atenção é o DeepSeek Sparse Attention (DSA): um mecanismo que indexa quais partes de contextos longos são relevantes e pula o cálculo do resto. Resultado: redução de aproximadamente 50% no custo computacional pra tarefas de contexto longo, sem perda mensurável de qualidade. Com janela de 128 mil tokens, isso faz diferença real em análise de código, documentos extensos e pipelines de RAG.
O balanceamento de carga entre especialistas também é diferente. Em vez de usar perdas auxiliares que conflitam com a otimização de qualidade, o DeepSeek implementou um termo de viés no mecanismo de roteamento. É elegante e funciona.
O elefante na sala: Huawei
Tudo isso roda em chips Huawei Ascend. Não por escolha técnica - por necessidade geopolítica. As restrições americanas à exportação de GPUs Nvidia para a China forçaram a DeepSeek a treinar em hardware doméstico. O drama entre OpenAI e Nvidia por chips que cobrimos aqui mostra que o suprimento de GPUs é o gargalo da indústria inteira. A DeepSeek fez da restrição uma vantagem competitiva.
O resultado é um modelo que alcança 82% de utilização de hardware nos chips Ascend e 512 petaflops de desempenho em FP16. Não é um H100, mas a eficiência do software compensa a diferença no silício.
Alex Platt, da DA Davidson, identificou o ponto crítico: “capacidade computacional representa uma limitação significativa, restringindo pesquisa algorítmica e soluções arquiteturais.” A própria DeepSeek reconheceu em paper de janeiro de 2026 que tem “certas limitações comparado a modelos closed-source de ponta como Gemini 3”, citando recursos computacionais. Mesmo assim, os benchmarks de matemática e código dizem outra coisa.
Open source muda a equação
O V3.2 é licenciado sob MIT. Significa que qualquer empresa pode baixar os pesos no Hugging Face, rodar em infraestrutura própria, fazer fine-tuning em dados proprietários e deployar em produção sem restrição comercial.
Pra rodar o modelo completo em FP16 são necessários cerca de 1,3 TB de memória - entre 8 e 16 GPUs H100 ou A100 de 80GB. Quantizado em 8 bits, cai pra 670 GB (4 a 8 GPUs). Em 4 bits, 335 GB (2 a 4 GPUs). Uma organização pode manter o modelo rodando internamente por US$20 mil a US$50 mil mensais, o que se torna competitivo com a própria API da DeepSeek a partir de 100 a 300 bilhões de tokens por mês.
No Brasil, onde a aposentadoria do GPT-4o forçou empresas a migrar pra modelos mais caros, o DeepSeek V3.2 abre uma porta que não existia. Startups brasileiras que gastam entre R$5 mil e R$15 mil por mês em APIs da OpenAI podem reduzir esse custo pra menos de R$1 mil com performance comparável em tarefas técnicas. A diferença paga um desenvolvedor.
O contexto de um ano
Quando o DeepSeek R1 apareceu em janeiro de 2025, Wall Street perdeu centenas de bilhões em valor de mercado num único dia. O medo era que a China tivesse encontrado um atalho pra IA de fronteira sem precisar do hardware americano. Um ano depois, a realidade é mais nuançada: a DeepSeek não matou ninguém, mas provou que a vantagem de custo da IA chinesa é real e sustentável.
Sete iterações do modelo em 11 meses. Cada uma mais eficiente que a anterior. E o êxodo de fundadores da xAI mostra que nem toda empresa americana de IA está em posição confortável pra competir.
O modelo R2 - o verdadeiro sucessor de raciocínio do R1 - ainda não foi lançado oficialmente. Estava previsto pra maio de 2025 e foi adiado por dificuldades no treinamento com os chips Ascend. Quando chegar, a conversa sobre quem lidera IA pode mudar de novo.
Enquanto isso, o V3.2 está ali: open source, mais barato que qualquer alternativa fechada, e batendo o GPT-5 em matemática. Os benchmarks não mentem. O preço por token, menos ainda.
Bruno Silva
Entusiasta de hardware e overclocker nas horas vagas
Especialista em hardware, benchmarks e overclock. Analisa componentes e tendências do mercado.
LEIA TAMBEM

O especialista que usa a física para desmascarar imagem feita por IA
É uma péssima, péssima ideia usar sua arroba do Instagram no seu WhatsApp
